Índice:
- 1 Introdução
- 2 DRI em tangará
- 2.1 Temas
- 2.2 Correntes Aspect
- 3 Padrões de Projeto Comum
- 4 Visão geral do esquema
- 5 Fusão de DRI Documentos
- 6 Alterações Versão
- 7 Element Reference
- 7.1 BODY
- 7.2 cell
- 7.3 div
- 7.4 DOCUMENT
- 7.5 field
- 7.6 figure
- 7.7 head
- 7.8 help
- 7.9 hi
- 7.10 instance
- 7.11 item
- 7.12 label
- 7.13 list
- 7.14 META
- 7.15 metadata
- 7.16 OPTIONS
- 7.17 p
- 7.18 pageMeta
- 7.19 params
- 7.20 reference
- 7.21 referenceSet
- 7.22 repository
- 7.23 repositoryMeta
- 7.24 row
- 7.25 table
- 7.26 trail
- 7.27 userMeta
- 7.28 value
- 7.29 xref
INTRODUÇÃO
Este manual descreve o Digital Repository Interface (DRI) que se aplica ao repositório digital DSpace e na interface baseada em XMLUI Manakin.O XMLUI DSpace é um sistema de UI (User Interface) abrangente. É centralizada e genérica, permitindo-lhe ser aplicada a todas as páginas DSpace, sendo eficaz para substituir o sistema de interface baseado em JSP. Sua capacidade de aplicar estilos específicos para arbitrariamente grandes conjuntos de páginas DSpace facilita significativamente a tarefa de adaptar o “look and feel” do DSpace. Isso também permite vários níveis de marcação, gerando credibilidade institucional para o repositório e coleções.
O Manakin, a segunda versão do DSpace XML UI, é composto por vários componentes, escritos usando Java, XML e XSL, e é implementado em Cocoon. O centro da interface é o documento XML, que é uma representação semântica de uma página DSpace. No Manakin, o documento XML adere a um esquema chamado de Digital Repository Interface (DRI), que foi desenvolvido em conjunto com o Manakin e é o assunto deste guia. Para o restante deste guia, os termos do documento XML, documento DRI e documento serão usados de forma intercambiável.
Este documento explica a finalidade do DRI, fornece uma visão geral da arquitetura e explica os padrões de design comuns. O apêndice inclui uma referência completa para os elementos utilizados no esquema DRI, uma representação gráfica da hierarquia dos elementos e uma tabela de elementos e atributos de referência rápida.
O PROPÓSITO DO ESQUEMA DRI
DRI é um esquema que comanda a estrutura do documento XML. Ela determina os elementos que podem estar presentes no documento e a relação dos elementos uns com os outros. Uma vez que todos os componentes Manakin geram documentos XML que aderem ao esquema DRI, o documento XML serve como camada de abstração. Dois componentes: temas e aspectos são essenciais para o funcionamento do Manakin e são brevementes descritos neste manual.
O DESENVOLVIMENTO DO ESQUEMA DRI
O esquema DRI foi desenvolvido para uso no Manakin. A escolha para desenvolver o nosso próprio esquema, em vez de adaptar um já existente veio depois de uma análise cuidadosa do propósito do esquema, bem como as lições aprendidas a partir de tentativas anteriores de personalização da interface DSpace. Uma vez que cada página DSpace no Manakin existe como um documento XML em algum ponto do processo, o esquema que descreve este documento tinha de ser capaz de representar estruturalmente todo o conteúdo, metadados e relações entre diferentes partes de uma página DSpace. Tinha que ser preciso o suficiente para evitar a perda de qualquer informação estrutural e ainda genérico o suficiente para permitir Temas com um certo grau de liberdade para expressar essa informação em um formato legível.
Esquemas populares como XHTML sofrem com o problema de não relacionar elementos em conjunto de forma explicita. Por exemplo, se um título precede um parágrafo, o título está relacionado com o parágrafo não porque ele é codificado como tal, mas porque ele precede o elemento parágrafo. Quando tenta-se traduzir essas estruturas dentro de formatos onde esses tipos de relacionamentos são explícitos, a tradução torna-se tediosa e potencialmente problemática. Esquemas mais estruturados, como TEI ou DocBook, são de domínio específico (muito parecido com o próprio DRI) e, portanto, não é adequado para nossos propósitos.
Decidimos também que o esquema deve suportar nativamente um padrão de metadados para a codificação de artefatos. Ao invés de codificar metadados de artefatos em elementos estruturais, como tabelas ou listas, o esquema incluiria artefatos como objetos codificados em um padrão particular. A inclusão de metadados em formato nativo permitiria que o Tema escolhesse o melhor método para exibir o artefato sem estar amarrado a uma estrutura particular.
Em última análise, optamos por desenvolver o nosso próprio esquema. Nós construímos o esquema DRI através da incorporação de outras normas, quando apropriado, como o esquema i18n do Cocoon para internacionalização, Dublin Core da DCMI e a o esquema METS da Library of Congress’s. O projeto de elementos estruturais derivou fundamentalmente do TEI , com alguns dos padrões de design de outras normas existentes, como DocBook e XHTML. Enquanto os elementos estruturais foram projetados para serem facilmente traduzidos em XHTML, eles preservam as relações semânticas para uso em linguagens mais expressivas.
DRI NO MANAKIN
O processo geral para o tratamento de uma requisição no DSpace XMLUI consiste em duas partes. A primeira parte constrói o documento XML e a segunda parte estiliza o Documento para a saída. No Manakin, as duas partes não são discretas, então são embrulhadas dentro de dois processos: Content Generation, que constrói uma representação XML da página, e Application Style, que estiliza o documento resultante. Content Generation é realizado pelo Aspect chaining, enquanto o Application Style é realizado por um tema.
TEMAS
Um tema é uma coleção de folhas de estilo XSL e arquivos de suporte, como imagens, estilos CSS, traduções e documentos de ajuda. As folhas de estilo XSL são aplicadas ao documento DRI para convertê-lo em um formato legível e dar-lhe estrutura e formatação visual. Os arquivos de suporte são usados para fornecer a página um específico look and feel, inserir imagens e outros meios de comunicação, traduzir o conteúdo e executar outras tarefas. O formato de saída usado atualmente é XHTML e os arquivos de suporte são geralmente limitados a CSS, imagens e JavaScript. Mais formatos de saída, como PDF ou SVG podem ser adicionados no futuro.
A instalação DSpace manakin pode ter vários temas associados. Quando aplicado a uma página, um tema determina a maioria do look and fell. Diferentes temas podem ser aplicados a diferentes conjuntos de páginas DSpace permitindo tanto a variedade de estilos entre as séries de páginas e a consistência dentro desses conjuntos. O arquivo de configuração xmlui.xconf determina quais temas são aplicados para as páginas DSpace (veja a seção XMLUI Configuration and Customization seção para mais informações sobre como instalar e configurar temas). Os temas podem ser configurados para aplicar-se a todas as páginas de um tipo específico, como browse-by-title, a todas as páginas de uma determinada comunidade ou uma coleção ou conjuntos de comunidades e coleções, e qualquer mistura dos dois. Eles também podem ser configurados para se aplicar a um página arbitrária ou um handle.
CHAIN ASPECTS – CADEIA DE ASPECTOS
Os Aspects Manakin são arranjos de componentes Cocoon (transformadores, ações, matchers, etc) que implementam um novo conjunto de recursos acoplados para o sistema. Estes aspectos são encadeados para formar todas as características do manakin. Cinco aspectos existem na instalação padrão do manakin, cada um lida com um determinado conjunto de características do DSpace, e muito mais pode ser adicionado ao implementar recursos extras. Todos os Aspectos tem um documento DRI como entrada e também geram um documento DRI como saída. Isso permite que os aspectos sejam unidos para formar uma cadeia de Aspect. Cada aspecto da cadeia leva um documento DRI como entrada, adiciona sua própria funcionalidade, e passa o documento modificado para o próximo Aspecto na cadeia.
DESIGN PATTERNS COMUNS
Existem vários padrões de projeto utilizados de forma consistente dentro do esquema DRI. Esta seção identifica a necessidade e descreve a implementação desses padrões. Três padrões são discutidos: questões de linguagem e de internacionalização, o atributo trio padrão ( id , n , erend ), e o uso de marcação orientada a estrutura.
LOCALIZAÇÃO E INTERNACIONALIZAÇÃO
Internacionalização é um componente muito importante do sistema de DRI. Ele permite que o conteúdo a ser oferecido em outras línguas com base na localidade do usuário e condicionada à disponibilidade de traduções, bem como datas atuais e moeda de forma localizada. Existem dois tipos de conteúdo: o conteúdo traduzido armazenado e exibido pelo próprio DSpace e conteúdo introduzido pelo processo de styling DRI nas transformações XSL. Ambos os tipos são tratados pelo transformador i18n do Cocoon sem levar em conta sua origem.
Quando o processo de geração de conteúdo produz um documento DRI, algum do conteúdo textual pode ser marcado com i18n elementos para significar que as traduções estão disponíveis para esse conteúdo. Durante o processo de aplicação de estilo, o tema também pode introduzir um novo conteúdo textual, marcando-o com i18n tags. Como resultado, após modelos XSL do tema são aplicadas ao documento DRI, o resultado final consiste em uma página DSpace marcado no formato de apresentação escolhido (como XHTML) com i18n elementos de ambos DSpace e conteúdo XSL. Este documento final é enviado através de transformador de i18n do Cocoon que traduz o texto marcado.
STANDARD ATTRIBUTE TRIPLET – PADRÃO TRIO DE ATRIBUTOS
Muitos elementos do sistema de DRI (todos os containers de nível superior, classes de caracteres e muitos outros) contém um ou vários dos três atributos padrão: id , n , e rend . Os atributos ID e n podem ser obrigatórios ou opcionais baseados no propósito do elemento, enquanto o atributo rend é sempre opcional. Os dois primeiros são usados para fins de identificação, enquanto que o terceiro é utilizado como uma pitada de exibição para o passo de styling.
A identificação é importante porque permite que elementos sejam separados de seus pares para a classificação, renderização em caso especial e outras tarefas. O primeiro atributo, ID , é o identificador global e é único para todo o documento. Qualquer elemento que contém um atributo ID pode, assim, ser referenciado exclusivamente por ele. O atributo ID de um elemento pode ser atribuído tanto explicitamente, ou gerado a partir da Java Class Path do objeto de origem se nenhum nome for dado. Embora todos os elementos que podem ser identificadas exclusivamente podem transportar o atributo ID, apenas aqueles que são independentes no seu contexto tem a necessidade de fazer isso. Por exemplo, as tabelas são obrigadas a terem uma identificação, pois precisam manter o significado independentemente da sua localização no documento, enquanto as linhas da tabela e células podem omitir o atributo já que seu significado depende do elemento pai.
O atributo n é simplesmente o nome atribuído ao elemento e que é utilizado para distinguir um elemento de seus pares imediatos. No exemplo de uma lista particular, todos os itens dessa lista terão nomes diferentes para distingui-los uns dos outros. Outras listas no documento, no entanto, também pode conter itens cujos nomes serão diferentes um do outro, mas idênticos aos da primeira lista. O atributo n de um elemento é, portanto, único apenas no âmbito do pai desse elemento e é usado principalmente para fins de classificação e prestação especial de uma certa classe de elementos, como, por exemplo, todos os primeiros itens em listas, ou todos os itens com o nome “browse”. O atributo n segue as mesmas regras como id para determinar se é ou não é exigido para um determinado elemento.
O último atributo no padrão trio é o rend. Ao contrário do id e n , o atributo rend pode consistir de vários valores de espaços delimitados e é opcional para todos os elementos que podem contê-lo. Seu objetivo é fornecer uma dica de renderização da camada intermediária do componente para estilizar o tema. Há vários casos, onde o conteúdo do atributo rend é descrito em detalhes e seu uso é incentivado. Esses casos são os elementos de ênfase hi , o elemento de divisão div, e o elemento list. Por favor, consulte o manual de Referência de Elementos para obter mais detalhes sobre eles.
MARCAÇÃO ORIENTADA A ESTRUTURA
O padrão de projeto final é o uso de marcação orientada a estrutura para o conteúdo transportado pelo documento XML. Uma vez gerado pela Cocoon, o documento contém dois tipos principais de informação: metadados sobre o repositório e seu conteúdo e o conteúdo real da página a ser exibida. Uma visão completa de metadados e marcação de conteúdo e sua relação com outros elementos é dada na próxima seção. Uma coisa importante a notar aqui, no entanto, é que a marcação do conteúdo é voltado para declarar explicitamente as relações estruturais entre os elementos ao invés de focar os aspectos de apresentação. Isso faz com que a marcação utilizada pelo documento seja mais semelhante ao TEI ou Docbook em vez de HTML. Por esta razão, templates XSL são utilizadas pelos temas para converter a marcação DRI estrutural para XHTML. Mesmo assim é feita uma tentativa para criar XHTML estrutural sempre que possível, deixando a apresentação inteiramente no CSS. Isso permite que o documento XML seja genérico o suficiente para representar qualquer página DSpace sem informar como ela deveria ser renderizada.
VISÃO GERAL DO ESQUEMA
O documento XML DRI consiste do elemento raiz document e três elementos de nível superior que contém dois tipos principais de elementos. Os três containers de nível superior são meta, body e options. Os dois tipos de elementos que eles contêm são metadados e conteúdo, levando metadados sobre a página e os conteúdos da página, respectivamente. A Figura 1 mostra a relação entre estes seis componentes.

Figura 1: Os dois tipos de conteúdo em três divisões principais de uma página DRI.
O elemento document é a raiz de todas as páginas da DRI e contém todos os outros elementos. Ele tem apenas um atributo, versão, que contém o número da versão do sistema DRI e o esquema usado para validar o documento produzido. Na hora de escrever o número da versão de trabalho é “1.1”.
O elemento meta é um elemento de nível superior com o número e contém todas as informações de metadados sobre a página, o usuário que a solicitou e o repositório que foi usado. Ele não contém elementos estruturais, pelo contrário, sendo o único container de elementos de metadados em um documento DRI. Os metadados armazenados pelo elemento meta é dividido em três grandes grupos: userMeta , pageMeta e objectMeta , cada um armazenando informação sobre o seu respectivo componente. Por favor, consulte as entradas de referência para mais informações sobre estes elementos.
O elemento options é outro elemento de nível superior que contém todas as opções de navegação e de ação disponíveis para o usuário. As opções são armazenados como itens de elementos da lista, divididas pelo tipo de ação que executam. Os cinco tipos de ações são: navegação, pesquisa, seleção de idioma, as ações que estão sempre disponíveis, e as ações que são dependentes do contexto. Os dois tipos de ação também conter sub-listas que contêm as ações disponíveis para usuários de diferentes níveis de acesso ao sistema. O elemento options não contém elementos de metadados e só pode fazer uso de um pequeno conjunto de elementos estruturais, ou seja, os elementos list e de seus filhos.
O último grande elemento superior é o elemento body. Ele contém todos os elementos estruturais em um documento DRI, incluindo as listas utilizadas pelo elemento options. Os elementos estruturais são usados para construir uma representação genérica de uma página DSpace. Qualquer página DSpace pode ser representada com uma combinação de elementos estruturais, o que por sua vez, podem ser transformados pelos modelos XSL em outro formato. Este é o principal mecanismo que permite que o DSpace XMLUI aplique templates uniformes e regras de estilo para todas as páginas do DSpace e é a diferença fundamental entre a abordagem JSP usada pelo DSpace.
O elemento body contém diretamente apenas um tipo de elemento: div.O elemento div serve como uma grande divisão de conteúdo e qualquer número deles pode ser contido pelo corpo . Além disso, as divisões são recursivas, permitindo que divs possam conter outros divs . É dentro destes elementos que todos os outros elementos estruturais estão. Esses elementos incluem tabelas, elementos de parágrafo p, listas, assim como os seus diversos elementos filhos. Nos níveis mais baixos desta hierarquia encontram-se os elementos de character container. Esses elementos, parágrafos p, table cells, listas de items, e o elemento de ênfase hi, contém o conteúdo textual de uma página DSpace, opcionalmente modificada com links, figuras e ênfase. Se a divisão dentro do qual a classe de caracteres está contida é marcado como interativa (via atributo interactive), esses elementos também podem conter campos de formulário interativos. Divisões marcadas como interativas também devem fornecer os atributos method e action para que seus campos sejam utilizados.
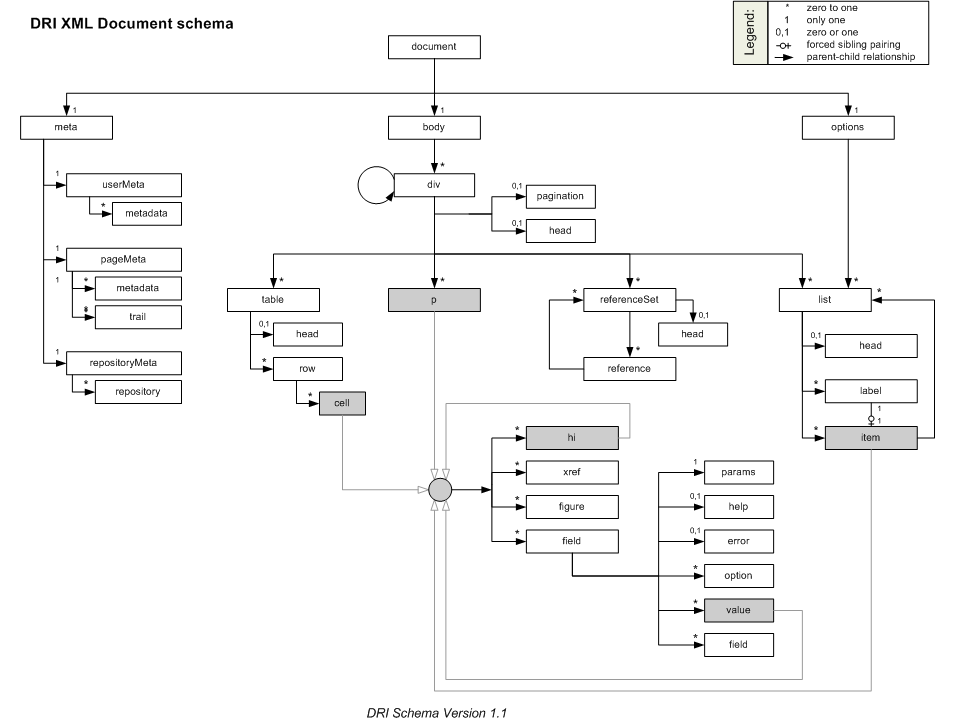
Figura 2: Todos os elementos no esquema DRI (versão 1.1).
MERGE DE DOCUMENTOS DRI
Tendo descrito a estrutura do documento DRI, bem como sua função no Aspect chains do Manakin, voltaremos agora a nossa atenção para o último detalhe de seu uso: fazer merge de dois documentos em um só. Existem várias situações em que a necessidade de fundir dois documentos surge. No Manakin, por exemplo, cada aspecto é responsável por adicionar uma funcionalidade diferente para uma página DSpace. Uma vez que cada instância de uma página tem que ser um documento DRI completo, cada aspecto é confrontado com a tarefa de fundir o documento gerado com outro documento gerado (e fundido em um único documento) previamente pela execução dos aspectos. Por esta razão existem regras que descrevem os elementos que podem ser mesclados e o que acontece com seus dados e elementos filhos no processo.
Ao mesclar dois documentos DRI, um é considerado o documento principal e o outro é um documento feeder que é adicionado dentro do principal. Os três container de nível superior (meta , body e options) de ambos os documentos são analisados individualmente e mesclados. No caso dos elementos options e meta, as tags filhas são pegas individualmente e são tratadas de forma diferente de seus irmãos.
Os elementos body são os mais fáceis de fundir: seus respectivos div filhos são preservados, juntamente com ele mesmo e estão agrupados sob um mesmo elemento. Assim, a nova tag body conterá todos os divs do documento principal seguido por todos os divs do feeder. No entanto, se duas divs têm os mesmos atributos n e rend (e no caso de uma div interativa os mesmos atributos action e method), essas divs serão fundidas em uma só. A div resultante terá os atributos id , n , e rend da div do documento principal e conterá todas as divs do documento principal seguido por todas as divs do feeder. Este processo continua recursivamente até que todas as divs sejam fundidas. Deve notar-se que duas divisões com regras de paginação separadas não podem ser fundidas em conjunto.
Merclar os elementos options é um pouco diferente. Primeiro, os elementos list sob options de ambos os documentos são comparados uns com os outros. Aqueles que forem únicos para ambos os documentos são simplesmente adicionados sob o novo elemento options, assim como divs sob o elemento body. Em caso de elementos duplicados, ou seja, elementos list que pertencem a ambos os documentos e tem o mesmo atributo n, as duas lists serão fundidas em uma só. O novo elemento list será composto do elemento head do documento principal, seguido dos pares label-item do documento principal, e finalmente, os pares label-item do feeder, desde que sejam diferentes daqueles do principal.
Finalmente, os elementos meta são fundidos bem como os elementos sob o body. Os três filhos de meta – userMeta , pageMeta e objectMeta – são fundidos individualmente, adicionando o conteúdo do feeder após o conteúdo do principal.
ALTERAÇÃO DE VERSÕES
O esquema DRI continuará a evoluir de acordo com as necessidades de design de interface. O atributo version do documento vai indicar qual a versão do esquema do documento está em conformidade. Na época o Manakin foi incorporado ao padrão de distribuição DSpace, a versão atual era “1.1”, porém as versões anteriores da interface Manakin podem usar a versão “1.0”.
ALTERAÇÃO 1.0 – 1.1
Houveram grandes mudanças estruturais entre estes dois números de versão. Vários elementos foram removidos do esquema: includeSet, include, objectMeta, and object. Originalmente todos os metadados para objetos foram incluídos em linha com o documento DRI, este provou ter vários problemas e foi removido na versão 1.1 do esquema. Em vez de incluir metadados em linha, foram incluídas referências externas para os metadados. Assim um elemento reference foi adicionado juntamente com referenceSet . Estes novos elementos funcionam como suas contrapartes na versão anterior, exceto sobre referenciar metadados contidos no elemento objectMeta que se referem a metadados em arquivos externos. Os elementos repository e repositoryMeta também foram modificados de forma semelhante removendo metadados em linha e referenciando documentos de metadados externos.
REFERÊNCIA DE ELEMENTOS
| Element | Attributes | Required? |
| BODY | ||
| cell | ||
| cols | ||
| id | ||
| n | ||
| rend | ||
| role | ||
| rows | ||
| div | ||
| action | required for interactive behavior | |
| behaviorSensitivFields | ||
| currentPage | ||
| firstItemIndex | ||
| id | required | |
| interactive | ||
| itemsTotal | ||
| lastItemIndex | ||
| method | required for interactive | |
| n | required | |
| nextPage | ||
| pagesTotal | ||
| pageURLMask | ||
| pagination | ||
| previousPage | ||
| rend | ||
| DOCUMENT | version | required |
| field | ||
| disabled | ||
| id | required | |
| n | required | |
| rend | ||
| required | ||
| type | required | |
| figure | ||
| rend | ||
| source | ||
| target | ||
| head | ||
| id | ||
| n | ||
| rend | ||
| help | ||
| hi | rend | required |
| instance | ||
| item | ||
| id | ||
| n | ||
| rend | ||
| label | ||
| id | ||
| n | ||
| rend | ||
| list | ||
| id | required | |
| n | required | |
| rend | ||
| type | ||
| META | ||
| metadata | ||
| element | required | |
| language | ||
| qualifier | ||
| OPTIONS | ||
| p | ||
| id | ||
| n | ||
| rend | ||
| pageMeta | ||
| params | ||
| cols | ||
| maxlength | ||
| multiple | ||
| operations | ||
| rows | ||
| size | ||
| reference | ||
| url | required | |
| repositoryID | required | |
| type | ||
| referenceSet | ||
| id | required | |
| n | required | |
| orderBy | ||
| rend | ||
| type | required | |
| repository | ||
| repositoryID | required | |
| url | required | |
| repositoryMeta | ||
| row | ||
| id | ||
| n | ||
| rend | ||
| role | required | |
| table | ||
| cols | required | |
| id | required | |
| n | required | |
| rend | ||
| rows | required | |
| trail | ||
| rend | ||
| target | ||
| userMeta | authenticated | required |
| value | ||
| optionSelected | ||
| optionValue | ||
| type | required | |
| xref | target | required |
BODY
Container de nível superior
O body é o principal elemento container para todo o conteúdo exibido para o usuário. Ele contém um conjunto de elementos div que agrupam o conteúdo em blocos de interação e exibição.
Parent
- document
Children
- div (qualquer)
Atributos
- Nenhum
<document version=1.0> <meta> ... </meta> <body> <div n="division-example1" id="XMLExample.div.division-example1"> ... </div> <div n="division-example2" id="XMLExample.div.division-example2" interactive="yes" action="www.DRItest.com" method="post"> ... </div> ... </body> <options> ... </options></document> |
cell
Rich Text Container
Elemento estrutural
O elemento cell contido em uma linha de uma tabela traz conteúdo para essa tabela. É um container de caracteres, como p, item, e hi e seu objetivo principal é exibir os dados textuais, possivelmente com com hyperlinks, blocos de enfatização de texto, imagens e campos de formulários. Cada cell pode ser anotada com uma role (sendo a mais comum “header” e “data”) e pode esticar em qualquer número de linhas e colunas. Como as cells não podem existir fora do seu container (row), seu atributo id é opcional.
Parent
- row
Children
- hi (qualquer)
- xref (qualquer)
- figure (qualquer)
- field (qualquer)
Atributos
- cols : (opcional) O número de colunas abrangidas pela célula.
- id : (opcional) Um identificador único do elemento.
- n : (opcional) Um identificador de local usado para diferenciar o elemento de seus irmãos.
- rend : (opcional) Uma dica de renderização usada para substituir o padrão de exibição do elemento.
- role : (opcional) Um atributo opcional para substituir as configurações da row onde a cell está contida.
- rows : (opcional) O número de linhas que a célula abrange.
<table n="table-example" id="XMLExample.table.table-example" rows="2" cols="3"> <row role="head"> <cell cols="2">Data Label One and Two</cell> <cell>Data Label Three</cell> ... </row> <row> <cell> Value One </cell> <cell> Value Two </cell> <cell> Value Three </cell> ... </row> ...</table> |
div
Elemento estrutural
O elemento div representa uma grande parte do conteúdo e pode conter uma grande variedade de elementos estruturais para apresentar conteúdo ao usuário. Ele pode conter parágrafos, tabelas e listas, bem como referências para informações armazenadas no artifactMeta, repositoryMeta, collections, and communities. O elemento div também é recursivo, permitindo-lhe ser ainda dividido em outros divs. As divs podem ser de dois tipos: interativas e estáticas. Os dois tipos são definidos através da utilização do atributo interactive e diferem na sua capacidade para conter o conteúdo interativo. Elementos filhos de divs marcadas como interativos podem conter campos do formulário, com atributos action e method da div que serve para resolver esses campos.
Parent
- body
- div
Children
- head (zero ou um)
- pagination (zero ou um)
- table (qualquer)
- p (qualquer)
- referenceSet (qualquer)
- list (qualquer)
- div (qualquer)
Atributos
- action : (necessário para interativo) O atributo action do formulário determina onde as informações do formulário deverão ser enviadas para processamento.
- behavior : (opcional para interativo) As opções de comportamento aceitáveis que podem ser usados neste formulário. O único valor possível definidos neste momento é “ajax”, o que significa que o formulário pode ser apresentado várias vezes para cada campo individual neste formulário. Observe que, se o formulário for enviado várias vezes é melhor que o behaviorSensitiveFields seja atualizado.
- behaviorSensitiveFields : (opcional para interativo) Uma lista de nomes de campos separados por espaço são sensíveis ao behavior. Estes campos devem ser atualizadas cada vez que um formulário é enviado com uma atualização completa da página (ou seja, ajax).
- currentPage : (opcional) Por divs paginados, o atributo currentPage indica o índice da página atualmente exibida para este div.
- firstItemIndex : (opcional) Para divs paginados, o atributo firstItemIndex indica o índice do primeiro item incluído nesta div.
- id : (obrigatório) um identificador único do elemento.
- interactive : Os valores aceitos (opcionais) são “yes”, “no”. Este atributo determina se o div é interativo ou estático. As divs interativas devem fornecer action e method e pode conter elementos field.
- itemsTotal : (opcional) Para divs paginados, o atributo itemsTotal indica quantos itens existem em todos os divs paginados.
- lastItemIndex : (opcional) Para divs paginados, o atributo lastItemIndex indica o índice do último item incluído nesta div.
- method : (necessário para interativos) Os valores aceitos são “get”, “post”, e “multipart”. Determina o método usado para passar os valores dos fields para o handler especificado pelo atributo action. O método multipart deve ser usado para upload de arquivos.
- n : (obrigatório) Um identificador de local utilizado para diferenciar o elemento de seus irmãos.
- nextPage : (opcional) Para divs paginados o atributo nextPage aponta para o URL da página seguinte do div, se ele existir.
- pagesTotal : (opcional) Para divs paginados, o atributo pagesTotal indica em quantas páginas os divs serão paginados.
- pageURLMask : (opcional) Para divs paginados, o atributo pageURLMask contém a máscara de uma URL para uma página específica dentro do conjunto paginado. O número da página de destino deve substituir a string {pageNum} da URL para gerar uma URL completa para essa página.
- pagination : valores aceitos (opcionais) são “simple”, “masked”. Este atributo determina se a div está espalhada por várias páginas. Divs paginadas simples devem fornecer os atributos previousPage, nextPage, itemsTotal, firstItemIndex, lastItemIndex. Divs paginadas masked devem fornecer os atributos currentPage, pagesTotal, pageURLMask, itemsTotal, firstItemIndex, lastItemIndex.
- previousPage : (opcional) Para divs paginados o atributo previousPage aponta para o URL da página anterior do div, se ele existir.
- rend : (opcional) Uma dica de renderização usada para substituir o padrão de exibição do elemento. No caso da tag div, é também recomenado incluir um label como “primary” ou “secondary”. Divs marcadas como principal contém conteúdo, enquanto divs secundárias contém informações auxiliares ou campos de suporte.
<body> <div n="division-example" id="XMLExample.div.division-example"> <head> Example Division </head> <p> This example shows the use of divisions. </p> <table ...> ... </table> <referenceSet ...> ... </referenceSet> <list ...> ... </list> <div n="sub-division-example" id="XMLExample.div.sub-division-example"> <p> Divisions may be nested </p> ... </div> ... </div> ...</body>
|
DOCUMENT
Document Root
O elemento document é o container raiz de um documento XMLUI. Todos os outros elementos estão contidos dentro dele, direta ou indiretamente. O único atributo que ele tem é a versão do esquema que está sendo usado.
Parent
- nenhum
Children
- meta (um)
- corpo (um)
- opções (um)
Atributos
- versão : (obrigatório) Número da versão do esquema que o documento segue. No momento os únicos números de versão válidos são “1.0” ou “1.1”. Iterações futuras deste esquema podem incrementar o número da versão.
<document version="1.1"> <meta> ... </meta> <body> ... </body> <options> ... </options></document> |
field
Text Container
Elemento estrutural
O elemento field é um container para todas as informações necessárias para criar um campo de formulário. O atributo type é orbigatório e determina o tipo do campo, enquanto as childrens tags possuem as informações sobre como construí-lo. Os fields só podem aparecer em divs “interativas”.
Parent
- cell
- p
- hi
- item
Childrens
- params (um)
- help (zero ou um)
- error (qualquer)
- option (qualquer – apenas com o tipo select)
- value (qualquer – apenas disponível nos campos do tipo: select, checkbox, ou rádio)
- field (um ou mais – só com o tipo de composite)
- ValueSet (qualquer)
Atributos
- disabled : (opcional) Valores aceitos são “yes” e “no”. Determina se o campo permite a entrada do usuário. A renderização de campos disabled podem variar de acordo com a mídia de implementação e de exibição.
- id : (obrigatório) Um identificador exclusivo para um elemento de campo.
- n : (obrigatório) Um identificador local não-exclusivo usado para diferenciar o elemento de seus irmãos dentro de uma divisão interativa. Este é o nome do campo de utilização, quando os dados são apresentados de volta para o servidor.
- rend : (opcional) Uma dica de renderização usada para substituir o padrão de exibição do elemento.
- required : (opcional) Os valores aceitos são “yes”, “no”. Determina se o campo é um componente obrigatório do formulário e, portanto, não pode ser deixado em branco.
- type : (obrigatório) Um atributo necessário para especificar o tipo de valor. Os types aceitos são:
- button : um botão que, quando ativado pelo usuário irá enviar o formulário com todos os campos para serem processados no servidor.
- checkbox : Um input booleano que pode ser selecionado pelo usuário. Um selectbox pode ter vários campos que compartilham o mesmo nome e cada um desses campos pode ser alternado de forma independente. Ele é diferente de um botão em que apenas um campo pode ser selecionado.
- file : Um input que permite que o usuário selecione os arquivos a serem anexados ao formulário. Note-se que uma formulário que usa um campo file deve usar o method multipart.
- hidden : Um input que não é exibido na tela e é escondido do usuário.
- password : um input de linha única, onde o texto de entrada é processado de modo a esconder os caracteres do usuário.
- radio : um input booleano que pode ser selecionado pelo usuário. Vários campos radio podem compartilhar o mesmo nome. Quando isto ocorre apenas um campo pode ser selecionado. Ele é diferente de um selectbox onde vários campos podem ser selecionados.
- select : um input de menu que permite ao usuário selecionar elementos a partir de uma lista de opções.
- text : um input de texto em única linha.
- textarea : um input de texto em multi-linha.
- composite : um input composto que vombina vários inputs em um único campo. Os campos que podem ser colocados em conjunto são: checkbox, password, select, text, and textarea. Quando os campos são combinados eles podem possuir vários valores combinados.
<p> <hi> ... </hi> <xref> ... </xref> <figure> ... </figure> ... <field id="XMLExample.field.name" n="name" type="text" required="yes"> <params size="16" maxlength="32"/> <help>Some help text with <i18n>localized content</i18n>.</help> <value type="raw">Default value goes here</value> </field></p> |
figure
Text Container
Elemento estrutural
O elemento figure é utilizado para incorporar uma referência a uma imagem ou um elemento gráfico. Pode ser misturada livremente com o texto e qualquer texto no interior da própria tag será usado como um caption ou uma descrição alternativa.
Parent
- cell
- p
- hi
- item
Children
- nenhum
Atributos
- rend : (opcional) Uma dica de renderização usado para substituir o padrão de exibição do elemento.
- fonte : (opcional) O source da imagem, usando uma URL ou uma entidade XML pré-definida.
- alvo : (opcional) Um target para uma imagem usada como um link, utilizando uma URL ou um id de um elemento existente como destino.
|
<p>
<hi> ... </hi> ... <xref> ... </xref> ... <field> ... </field> ... <figure source="www.example.com/fig1"> This is a static image. </figure> <figure source="www.example.com/fig1" target="www.example.net"> This image is also a link. </figure> ...</p> |
head
Text Container
Elemento estrutural
O elemento head é usado principalmente como um label associado ao seu elemento pai. A renderização é determinada pela tag pai, mas pode ser substituída pelo atributo rend. Uma vez que não pode ser apenas um elemento head associado com uma tag particularo, o atributo on não é necessário, e o atributo id é opcional.
Parent
- div
- table
- list
- referenceSet
Children
- nenhum
Atributos
- id : (opcional) um identificador único do elemento
- n : (opcional) Um identificador de local usado para diferenciar o elemento de seus irmãos
- rend : (opcional) Um hint de renderização usado para substituir o padrão de exibição do elemento.
|
<div …>
<head> Este é um cabeçalho simples associado com o seu elemento div. </head> <div ...> <head rend="green"> Este cabeçalho será verde. </head> <p> <head> Um cabeçalho com <i18n>conteúdo localizado</i18n>. </head> ... </p> </div> <table ...> <head> ... </head> ... </table> <list ...> <head> ... </head> ... </list> ...</body> |
help
Text Container
Elemento estrutural
O elemento opcional help é usado para fornecer instruções de ajuda em texto simples e normalmente está dentro de um elemento field. O método usado para processar o texto de ajuda está no topo do tema.
Parent
- field
Children
- nenhum
Atributos
- Nenhum
|
<p>
<hi> ... </hi> ... <xref> ... </xref> ... <figure> ... </figure> ... <field id="XMLExample.field.name" n="name" type="text" required="yes"> <params size="16" maxlength="32" /> <help>Algum help com <i18n>conteúdo localizado</i18n>.</help> </field> ...</p> |
hi
Rich Text Container
Elemento estrutural
O elemento hi é usado para dar ênfase num texto e ocorre em containers de caracteres como p e list. Pode ser misturado livremente com o texto, e qualquer texto dentro da tag hi será realçada de uma maneira especificada pelo atributo rend. Além disso, o elemento hi é o único componente container de texto que tem um container rich text dentro dele, o que significa que pode conter outras tags além de texto simples. Isso permite que ele contenha outros container de texto, incluindo outras tags hi.
Parent
- cell
- p
- item
- hi
Childrens
- hi (qualquer)
- xref (qualquer)
- figure (qualquer)
- field (qualquer)
Atributos
- rend : (obrigatório) Usado para especificar o tipo exato de ênfase para aplicar ao texto contido. Os valores mais comuns incluem, mas não estão limitados a “bold”, “italic”, “underline”, and “emph”.
|
<p>
This text is normal, while <hi rend="bold">this text is bold and this text is <hi rend="italic">bold and italic.</hi></hi></p> |
instância
Elemento estrutural
O exemplo elemento contém o valor associado a várias instâncias de um campo de formulário. Os campos codificados como uma instância também deve incluir os valores de cada instância como um campo oculto. O campo oculto deve ser anexado com o número de índice para a instância. Assim, se o campo é “nome” cada instância seria nomeado “firstName_1”, “firstName_2”, “firstName_3”, etc ..
Parente
- campo
Crianças
- valor
Atributos
- Nenhum listado ainda.
Exemplo necessário. |
item
Rich Text Container
Elemento estrutural
O item de elemento é uma rica contêiner de texto usado para exibir dados textuais em uma lista. Como um contêiner de texto rico que pode conter hiperligações, enfatizou blocos de texto, imagens e campos de formulário, além de texto simples.
O item de elemento pode ser associado com um rótulo que o precede directamente. O esquema exige que se um artigo em uma lista tem um associado rótulo , em seguida, todos os outros itens devem ter um também. Isso reduz o problema de conexões soltas entre os elementos que é comumente encontradas em XHTML, uma vez que cada item na lista particular tem a mesma estrutura.
Parente
- lista
Crianças
- oi (qualquer)
- xref (qualquer)
- figura (qualquer)
- campo (qualquer)
- lista (qualquer)
Atributos
- ID : (opcional) um identificador único do elemento
- n : (opcional) Um identificador de local não-exclusiva usada para diferenciar o elemento de seus irmãos
- rend : (opcional) Uma dica de renderização usado para substituir o padrão de exibição do elemento.
<Lista de n = "lista-exemplo" id = "XMLExample.list.list-exemplo" > <head> Lista Exemplo </ head> <item> Este é o primeiro item </ Item> <item> Este é o segundo item com <hi ...> destaque texto </ oi>, <xref ...> um link </ xref> e um <figura ...> Imagem </ figure>. </ Item> ... <Lista de n = "list-example2" id = "XMLExample.list.list-example2" > <head> Lista Exemplo </ head> ITEM <label> UM: </ label> <item> Este é o primeiro item </ Item> ITEM <label> DOIS: </ label> <item> Este é o segundo item com <hi ...> destaque text </ oi>, <xref ...> um link </ xref> e um <figura ...> Imagem </ figure>. </ Item> ITEM <label> TRÊS: </ label> <item> Este é o terceiro item com um <field ...> ... </ field> </ Item> ... </ List> <item> Este é o terceiro item na lista </ Item> ...</ List> |
etiqueta
Container Texto
Elemento estrutural
O rótulo elemento é associado a um item e anota esse item com um número, uma descrição textual de algum tipo, ou uma bala simples.
Parente
- item
Crianças
- nenhum
Atributos
- ID : (opcional) um identificador único do elemento
- n : (opcional) Um identificador de local usada para diferenciar o elemento de seus irmãos
- rend : (opcional) Um atributo rend opcional fornece uma dica sobre como o rótulo deve ser processado, independente do seu tipo.
<Lista de n = "lista-exemplo" id = "XMLExample.list.list-exemplo" > <head> Lista Exemplo </ head> <label> 1 </ label> <item> Este é o primeiro item </ item> <label> 2 </ label> <item> Este é o segundo item com <hi ...> destaque texto </ oi>, <xref ...> um link </ xref> e um <figura ...> Imagem </ figure>. </ Item> ... <Lista de n = "list-example2" id = "XMLExample.list.list-example2" > <head> Exemplo Sublist </ head> ITEM <label> UM: </ label> <item> Este é o primeiro item </ item> ITEM <label> DOIS: </ label> <item> Este é o segundo item com <hi ...> destaque text </ oi>, <xref ...> um link </ xref> e um <figura ...> Imagem </ figure>. </ Item> ITEM <label> TRÊS: </ label> <item> Este é o terceiro item com um <field ...> ... </ field> </ Item> ... </ List> <item> Este é o terceiro item da lista </ item> ...</ List> |
lista
Elemento estrutural
A lista elemento é usado para exibir conjuntos de dados sequenciais. Ele contém um opcional cabeça elemento, bem como qualquer número deitens e lista elementos. itens contêm informações textuais, enquanto sublists conter outros itens ou lista elementos. Um artigo pode também ser associado com um rótulo elemento que anota um item com um número, uma descrição textual de algum tipo, ou um marcador simples. O tipo de lista (ordenada, com marcadores, brilho, etc) é então determinada tanto pelo conteúdo das etiquetas em itens ou por um valor explícito do tipode atributo. Note que, se os rótulos são usados em conjunto com quaisquer itens em uma lista, todos os itens da lista devem ter um rótulo .Também é recomendado para evitar a mistura de etiqueta estilos menos que um tipo explícito é especificado.
Parente
- div
- lista
Crianças
- cabeça (zero ou um)
- rótulo (qualquer)
- item (qualquer)
- lista (qualquer)
Atributos
- ID : (obrigatório) Um identificador exclusivo do elemento
- n : (obrigatório) Um identificador de local utilizado para diferenciar o elemento de seus irmãos
- rend : (opcional) Um atributo rend opcional fornece uma dica sobre como a lista deve ser processado, independente do seu tipo. Os valores mais comuns são, mas não se limitando a:
- alfabeto : A lista deve ser processado como um índice alfabético
- colunas : A lista deve ser prestados em colunas de comprimento igual, conforme determinado pelo tema.
- columns2 : A lista deve ser apresentado em duas colunas iguais.
- columns3 : A lista deve ser apresentado em três colunas iguais.
- horizontal : A lista deve ser processado na horizontal.
- numérico : A lista deve ser processado como um índice numérico.
- Vertical : A lista deve ser processado verticalmente.
- digite : (opcional) Um atributo opcional para especificar explicitamente o tipo de lista. Na ausência deste atributo, o tipo de uma lista vai ser inferida a partir da presença e conteúdo dos rótulos em seus itens. Os valores aceitos são:
- forma : Usado para listas de formulário que consistem em uma série de campos.
- marcadores : Utilizado para listas com os itens marcados de bala.
- gloss : Usado para as listas que consistem em um conjunto de termos técnicos, cada uma marcada com uma etiqueta de elemento e acompanhado pela definição marcado como um item de elemento.
- ordenou : Utilizado para listas com itens numerados ou com letras.
- progresso : Usado para listas constituídos por um conjunto de etapas sendo realizadas para realizar uma tarefa. Para este tipo de aplicação, cada ponto na lista deve representar um passo e ser acompanhado de uma etiqueta que contém o nome displayable para a etapa. O artigo contém uma referência externa que referencia o passo. Além disso, o rend atributo no item de elemento deve ser: “disponível” (ou seja, o usuário pode pular para o passo usando o fornecido xref ), “indisponível” (o usuário não atender aos requisitos para saltar para o passo), ou “corrente “(o usuário está atualmente no passo)
- simples : Utilizado para listas com itens não marcados com números ou marcadores.
<div ...> ... <Lista de n = "lista-exemplo" id = "XMLExample.list.list-exemplo" > <head> Lista Exemplo </ head> <item> ... </ item> <item> ... </ item> ... <Lista de n = "list-example2" id = "XMLExample.list.list-example2" > <head> Exemplo Sublist </ head> <label> ... </ label> <item> ... </ item> <label> ... </ label> <item> ... </ item> <label> ... </ label> <item> ... </ item> ... </ List> <label> ... </ label> <item> ... </ item> ... </ List></ Div> |
META
Nível superior-Container
A meta elemento é um elemento de nível superior e existe diretamente dentro do documento elemento. Ele serve como um elemento de recipiente para todos os metadados associados a um documento dividido em categorias, de acordo com o tipo de metadados que eles carregam.
Parente
- documento
Crianças
- userMeta (um)
- pageMeta (um)
- repositoryMeta (um)
Atributos
- Nenhum
<Versão do documento = 1.0 > <meta> <userMeta> ... </ userMeta> <pageMeta> ... </ pageMeta> <repositoryMeta> ... </ repositoryMeta> </ Meta> <body> ... </ body> <opções> ... </ Opções></ Documento> |
metadados
Container Texto
Elemento estrutural
O metadados elemento carrega informações de metadados genérico na forma de um par atributo-valor. O tipo de informação que ele contém é determinada por dois atributos: elemento , que especifica o tipo geral de metadados armazenados, e um opcional qualificador atributo que restringe o tipo baixo. A representação padrão para esse par é element.qualifier. Os metadados real está contida no texto da etiqueta em si.Além disso, uma linguagem atributo pode ser utilizado para especificar o idioma utilizado para a entrada de metadados.
Parente
- userMeta
- pageMeta
Crianças
- nenhum
Atributos
- elemento : (obrigatório) O nome de um campo de metadados.
- língua : (opcional) Um atributo opcional para especificar o idioma utilizado na tag de metadados.
- qualificador : (opcional) Uma postfix opcional para o nome do campo usado para diferenciar os nomes.
<meta> <userMeta> <Elemento de metadados = "identificador" qualificador = "nome" > Bob </ Metadata> <elemento de metadados = "identificador" qualificador = "Sobrenome" > Jones </ Metadata> <metadata ...> ... </ Metadata> ... </ UserMeta> <pageMeta> <elemento de metadados = "direitos" Qualificador = "accessRights" > usuário </ metadata> <metadata ...> ... </ Metadata> ... </ PageMeta></ Meta> |
OPÇÕES
Nível superior-Container
O opções de elemento é o principal recipiente para todas as ações e opções de navegação disponíveis para o usuário. Ele consiste em um número qualquer de lista elementos cujos itens contêm informações e ações de navegação. Embora qualquer lista de opções de navegação pode ser contida neste elemento, sugere-se que, pelo menos, os seguintes cinco listas ser incluídos.
Parente
- documento
Crianças
- lista (qualquer)
Atributos
- Nenhum
<Versão do documento = 1.0 > <meta> ... </ meta> <body> ... </ body> <opções> <Lista de n = "navegação à example1" id = "XMLExample.list.navigation-example1" > <head> Exemplo Lista de Navegação 1 </ head> <item> <xref target = "/ link / to / opção" > Opção Um </ xref> </ item> <item> <xref target = "/ link / to / opção" > Opção dois </ xref> </ item> ... </ List> <Lista de n = "navegação à example2" id = "XMLExample.list.navigation-example2" > <head> Exemplo Lista de Navegação 2 </ head> <item> <xref target = "/ link / to / opção" > Opção Um </ xref> </ item> <item> <xref target = "/ link / to / opção" > Opção dois </ xref> </ item> ... </ List> ... </ Opções></ Documento> |
p
Rich Text Container
Elemento estrutural
O p elemento é uma rica contêiner de texto usado por divs para exibir dados textuais em um formato de parágrafo. Como um contêiner de texto rico que pode conter hiperligações, enfatizou blocos de texto, imagens e campos de formulário, além de texto simples.
Parente
- div
Crianças
- oi (qualquer)
- xref (qualquer)
- figura (qualquer)
- campo (qualquer)
Atributos
- ID : (opcional) um identificador único do elemento.
- n : (opcional) Um identificador de local usada para diferenciar o elemento de seus irmãos.
- rend : (opcional) Uma dica de renderização usado para substituir o padrão de exibição do elemento.
<Div n = "divisão-exemplo" id = "XMLExample.div.division-exemplo" > <p> Este é um parágrafo normal. </ P> Este texto é normal, enquanto <oi rend = "bold" > este texto está em negrito e este texto é <oi rend = "italic" > negrito e itálico. </ oi> </ oi> </ P> Este parágrafo contém uma <xref target = "/ link / target" > link </ xref>, uma estática <figura source = "/ imagem.jpg" > imagem </ figure>, e <figura target = "/ Link / target" source = "/ imagem.jpg" > link da imagem. </ figure> </ P></ Div> |
pageMeta
Metadados Elemento
O pageMeta elemento contém metadados associados com o próprio documento. Ele contém genéricos metadados elementos para transportar o conteúdo, e qualquer número de trilha elementos para fornecer informações sobre a localização atual do usuário no sistema. Valores obrigatórios e sugeridos para metadados elementos contidos no pageMeta incluem, mas não estão limitados a:
- browser (sugerido): agente de navegação do usuário, como relatado para servidor na solicitação HTTP.
- browser.type (sugerido): A família do navegador em geral como forma derivada do campo de metadados browser. Os valores possíveis podem incluir “MSIE” (para o Microsoft Internet Explorer), “Opera” (para o navegador Opera), “Apple” (para navegadores baseados kit web Apple), “Gecko” (no Netscape, Mozilla e navegadores baseados Firefox) , ou “Lynx” (para navegadores baseados em texto).
- browser.version (sugerido): A versão do navegador como relatado por solicitação HTTP.
- contextPath (obrigatório): A URL base do sistema Digital Repository.
- redirect.time (sugerido): O tempo que deve decorrer antes que a página é redirecionada para um endereço especificado pelo redirect.urlmetadados elemento.
- redirect.url (sugerido): O destino URL de uma página de redirecionamento
- título (obrigatório): O título do documento / página que o usuário navegando.
Veja o metadados e trilha entradas tag para mais informações sobre a sua estrutura.
Parente
- meta
Crianças
- metadados (qualquer)
- trilha (qualquer)
Atributos
- Nenhum
<meta> <userMeta> ... </ userMeta> <pageMeta> <Elemento de metadados = "title" > Exemplo DRI página </ metadata> <Metadados elemento = "contextPath" > / XMLUI / </ metadata> <metadata ...> ... </ metadata> ... <Fonte trilha = "123456789/6" > Um item de migalha de pão </ Trilha> <trail ...> ... </ trilha> ... </ PageMeta></ Meta> |
params
Componente estrutural
O params elemento identifica parâmetros extras usados para construir um campo de formulário. Existem vários atributos que podem estar disponíveis para este elemento, dependendo do tipo de campo.
Parente
- campo
Crianças
- nenhum
Atributos
- cols : (opcional) O número padrão de colunas que a área de texto deve espalhar. Isto aplica-se apenas aos tipos de campo textarea.
- maxlength : (opcional) O comprimento máximo que o tema deve aceitar para a entrada de formulário. Isso se aplica a tipos de texto e de campo de senha.
- múltipla : (opcional) sim / não valor. Determine se o campo pode aceitar vários valores para o campo. Isso se aplica somente para selecionar listas.
- operações : (opcional) As operações possíveis que podem ser pré-formados sobre este campo. Os valores possíveis são “add” e / ou “excluir”. Se ambas as operações são possíveis, então eles devem ser fornecidos como uma lista separada por espaços. O “add” operações indica que pode haver vários valores para este campo e que o usuário pode adicionar ao conjunto um de cada vez. O front-end deve processar um botão que permite ao usuário adicionar mais campos ao conjunto. O botão deve ser nomeado o nome do campo adicionados com a string “_ADD”, assim se o nome do campo é “Nome” o botão deve ser chamado de “firstName_add.” O “delete” operação indica que pode haver vários valores para este campo cada do qual pode ser removido a partir do conjunto. O front-end deve processar uma caixa de seleção de cada valor do campo, com exceção do primeiro, A caixa de seleção deve ser nomeado o nome do campo adicionados com a string “_selected”, assim se o nome do campo é “Nome” na caixa de seleção deve ser chamado de “firstName_selected “e o valor de cada caixa sucessivo deverá ser o nome de campo. O front-end deve também tornar um botão delete. O nome do botão de exclusão deve ser o nome do campo adicionados com a string “_delete”.
- linhas : (opcional) O número padrão de linhas que a área de texto deve espalhar. Isto aplica-se apenas aos tipos de campo textarea.
- Tamanho : O tamanho padrão (opcional) para um campo. Isso se aplica ao texto, senha e selecione os tipos de campo.
<p> <Id = campo "XMLExample.field.name" n = "nome" type = "text" required = "yes" > <Tamanho params = "16" maxlength = "32" /> <help> algum texto de ajuda com <i18n> localizada conteúdo </ i18n>. </ help> < padrão > Valor padrão vai aqui </ default > </ Field></ P> |
referência
Metadados elemento de referência
referência é um elemento de referência utilizado para acessar informações armazenadas em um arquivo de metadados externos. A url atributo é usado para localizar o arquivo de metadados externos. O tipo de atributo fornece uma descrição curta limitado do tipo do objeto referenciado.
referência elementos podem ser tanto contido por includeSet elementos e conter includeSets si, tornando a estrutura recursiva.
Parente
- referenceSet
Crianças
- referenceSet (zero ou mais)
Atributos
- url : (obrigatório) A url para o arquivo de metadados externos.
- repositoryIdentifier : (obrigatório) Uma referência ao repositoryIdentifier do repositório.
- digite : (opcional) Descrição do tipo do objeto de referência.
<IncludeSet n = "lista de browse"id = "lista XMLTest.includeSet.browse" > <Referência url = "/ metadata/handle/123/4/mets.xml"repositoryID = "123" type = "DSpaceItem "/> <referência url =" / metadata / punho / 123 / 5 / mets.xml "repositoryID = "123" /> ... </ IncludeSet> |
referenceSet
Metadados elemento de referência
O referenceSet elemento é um recipiente de artefato ou referências de repositório.
Parente
- div
- referência
Crianças
- cabeça (zero ou um)
- referência (qualquer)
Atributos
- ID : (obrigatório) Um identificador exclusivo do elemento
- n : (obrigatório) identificador local usado para diferenciar o elemento de seus irmãos
- orderBy : (opcional) Uma referência ao campo de metadados que determina a ordenação dos artefatos ou objetos de repositório dentro do conjunto. Quando o esquema de metadados Dublin Core é usado este atributo deve ser o valor element.qualifier que o conjunto é classificada por. Como exemplo, para um navegar pela lista de títulos, o valor deve ser sortedBy = título, enquanto que para navegar pela lista de data deve ser sortedBy = date.created
- rend : (opcional) Uma dica de renderização usado para substituir o padrão de exibição do elemento.
- Tipo : (obrigatório) Determina o nível de detalhe para os metadados dado. Os valores aceitos são:
- summaryList : Indica que os metadados de artefatos referenciados ou objetos de repositório deve ser usado para construir uma representação de lista que é adequado para a rápida varredura.
- summaryView : Indica que os metadados de artefatos referenciados ou objetos de repositório deve ser usado para construir uma visão parcial de um ou mais objetos referenciados.
- detailList : Indica que os metadados de artefatos referenciados ou objetos de repositório deve ser usado para construir uma representação de lista que fornece uma visão completa ou quase completa, os objetos referenciados. Se esse ponto de vista é possível ou diferente summaryView depende em grande parte do repositório na mão eo tema de execução.
- detailView : Indica que os metadados de artefatos referenciados ou objetos de repositório deve ser usado para exibir informações completas sobre o objeto referenciado. Prestação de várias referências incluídas no âmbito deste tipo é até o tema.
<div ...> <head> Exemplo Divisão </ head> <p> ... </ p> <table> ... </ table> <list> ... </ List> <ReferenceSet n = "lista de browse"id = "XMLTest.referenceSet.browse-list" type = "summaryView"informationModel = "DSpace" > <head> Um cabeçalho para o includeset </ head> <Referênciaurl = "/ metadata/handle/123/34/mets.xml" /> <Referênciaurl = "" metadados / punho / 123 / 34 / mets.xml /> </ ReferenceSet> ... </ P> |
repositório
Metadados Elemento
O repositório elemento é usado para descrever o repositório. Seu principal componente é um conjunto de metadados estruturais que a informação transportadora em como os objetos do repositório sob objectMeta estão relacionados uns aos outros. O principal método de codificação estes relacionamentos na altura da elaboração deste documento é um documento SM, embora outros formatos, como RDF, podem ser empregues no futuro.
Parente
- repositoryMeta
Crianças
- nenhum
Atributos
- repositoryID : requiredA identificador único atribuído a um repositório. Ele é referenciado pelo objeto elemento para indicar o repositório que atribuiu seu identificador.
- url : requiredA url para o arquivo de metadados METS externo para o repositório.
<repositoryMeta> <Repositório repositoryID = "123456789" url = "/ metadata/handle/1234/4/mets.xml" /></ RepositoryMeta> |
repositoryMeta
Metadados Elemento
O repositoryMeta elemento contém referências metadados sobre os repositórios utilizados no utilizado ou referenciadas no documento. Ele pode conter qualquer número de repositórios elementos.
Veja o repositório de entrada tag para mais informações sobre a estrutura do repositório de elementos.
Parente
- Meta
Crianças
- repositório (qualquer)
Atributos
- Nenhum
<meta> <userMeta> ... </ usermeta> <pageMeta> ... </ pageMeta> <repositoryMeta> <Repositório repositoryIID = "..." url = "..." /> </ RepositoryMeta></ Meta> |
linha
Elemento estrutural
O elemento de linha está contido dentro de um quadro e serve como um recipiente de células elementos. A requerida papel atributo determina como a linha e suas células são prestados.
Parente
- mesa
Crianças
- celular (qualquer)
Atributos
- ID : (opcional) um identificador único do elemento
- n : (opcional) Um identificador de local usada para diferenciar o elemento de seus irmãos
- rend : (opcional) Uma dica de renderização usado para substituir o padrão de exibição do elemento.
- papel : (obrigatório) Indica que tipo de informação a linha carrega. Os valores possíveis incluem “cabeçalho” e “dados”.
<Table n = "table-exemplo" id = "XMLExample.table.table-exemplo" linhas = "2" cols = "3" > <Linha role = "cabeça" > <Cols celulares = "2" > Rótulo de Dados Um e Dois </ celular> Rótulo de Dados <célula> Três </ celular> ... </ Row> <row> <célula> Valor Um </ celular> <célula> Valor Dois </ celular> <célula> Valor Três </ celular> ... </ Row> ...</ Table> |
mesa
Elemento estrutural
A tabela de elemento é um recipiente para informações apresentadas em formato tabular. Ele consiste em um conjunto de linhas elementos e um opcional cabeçalho .
Parente
- div
Crianças
- cabeça (zero ou um)
- linha (qualquer)
Atributos
- cols : (obrigatório) O número de colunas na tabela.
- ID : (obrigatório) Um identificador exclusivo do elemento
- n : (obrigatório) Um identificador de local utilizado para diferenciar o elemento de seus irmãos
- rend : (opcional) Uma dica de renderização usado para substituir o padrão de exibição do elemento.
- linhas : (obrigatório) O número de linhas na tabela.
<Div n = "divisão-exemplo" id = "XMLExample.div.division-exemplo" > <Table n = "tabela1" id = "XMLExample.table.table1" linhas = "2" cols = "3" > <Papel linha = "cabeça" > <Cols celulares = "2" > Rótulo de Dados Um e Dois </ celular> Rótulo de Dados <célula> Três </ celular> ... </ Row> <row> <célula> Valor Um </ celular> <célula> Valor Dois </ celular> <célula> Valor Três </ celular> ... </ Row> ... </ Table> ...</ Div> |
trilha
Container Texto
Metadados Elemento
A trilha elemento traz informações sobre a localização atual do usuário no sistema relativo de página raiz do repositório. Cada instância do elemento serve como um link no caminho da raiz para a página atual.
Parente
- pageMeta
Crianças
- nenhum
Atributos
- rend : (opcional) Uma dica de renderização usado para substituir o padrão de exibição do elemento.
- alvo : (opcional) Um atributo opcional para especificar um URL de destino para um elemento trilha servindo como um hiperlink. O texto no interior do elemento vai ser utilizado como o texto da ligação.
<pageMeta> <Elemento de metadados = "title" > Exemplo DRI página </ metadata> <Metadados elemento = "contextPath" > / XMLUI / </ metadata> <metadata ...> ... </ metadata> ... <Alvo trilha = "/ myDSpace" > Um item de miolo de pão apontando para um página. </ Trilha> <trail ...> ... </ trilha> ...</ PageMeta> |
userMeta
Metadados Elemento
O userMeta elemento contém metadados associados com o usuário que solicitou o documento. Ele contém genéricos metadados elementos, que por sua vez transportam as informações. Valores obrigatórios e sugeridos para metadados elementos contidos no userMeta incluir, mas não limitado a:
- identificador (sugerido): um identificador único associado com o usuário.
- identifier.email (sugerido): endereço de e-mail do usuário solicitante.
- identifier.firstName (sugerido): O primeiro nome do usuário solicitante.
- identifier.lastName (sugerido): O sobrenome do usuário solicitante.
- identifier.logoutURL (sugerido): A URL que o usuário será levado para quando sair.
- identifier.url (sugerido): Uma referência url para a página do usuário no repositório.
- language.RFC3066 (sugerido): código de seleção de idioma de preferência do usuário solicitante como descrever por RFC3066
- rights.accessRights (obrigatório): determina o escopo de ações que um usuário pode executar no sistema. Os valores aceitos são:
- nenhum: O usuário está ou não autenticado ou não tem uma conta válida no sistema
- usuário: O usuário é autenticado e tem uma conta válida no sistema
- admin: O usuário é autenticado e pertence ao grupo administrativo do sistema
Veja o metadados entrada tag para mais informações sobre a estrutura de metadados elementos.
Parente
- meta
Crianças
- metadados (qualquer)
Atributos
- autenticados : (obrigatório) Os valores aceitos são “sim”, “não”. Determina se o usuário foi autenticado pelo sistema.
<meta> <userMeta> <Elemento de metadados = "identificador" qualificador = "email" > bobJones @ tamu . edu </ metadata> <Elemento de metadados = "identificador" qualificador = "nome" > Bob </ metadata> <Elemento de metadados = "identificador" qualificador = "Sobrenome" > Jones </ metadata> <Elemento de metadados = "direitos" Qualificador = "accessRights" > usuário </ metadata> <metadata ...> ... </ metadata> ... <Fonte trilha = "123456789/6" > Um item de miolo de pão </ trilha> <trail ...> ... </ trilha> ... </ UserMeta> <pageMeta> ... </ pageMeta></ Meta> |
valor
Rich Text Container
Elemento estrutural
O elemento de valor contém o valor associado a um campo de formulário e podem servir a um propósito diferente para vários tipos de campo. O elemento de valor é composto por dois sub-elementos: o elemento bruto, que armazena o valor não processado diretamente do usuário de outra fonte, eo elemento interpretado que armazena o valor em um formato adequado para exibição para o usuário, possivelmente incluindo rico marcação de texto.
Parente
- campo
Crianças
- oi (qualquer)
- xref (qualquer)
- figura (qualquer)
Atributos
- optionSelected : (opcional) Um atributo opcional para selecionar, caixa de seleção e campos de rádio para determinar se o valor deve ser selecionado ou não.
- optionValue : (opcional) Um atributo opcional para selecionar, caixa de seleção e campos de rádio para determinar o valor que deve ser retornado quando esse valor é selecionado.
- Tipo : (obrigatório) Um atributo necessário para especificar o tipo de valor. Tipos aceitos são:
- crua : O tipo de matéria-armazena o valor não processado diretamente do usuário de outra fonte.
- interpretado : O tipo interpretado armazena o valor em um formato adequado para exibição para o usuário, possivelmente incluindo rico marcação de texto.
- padrão : O tipo padrão armazena um valor fornecido pelo sistema, utilizado quando há outros valores são fornecidos.
<p> <hi> ... </ oi> <xref> ... </ xref> <figure> ... </ figure> <Id = campo "XMLExample.field.name" n = "nome" type = "text" required = "yes" > <Tamanho params = "16" maxlength = "32" /> <help> algum texto de ajuda com <i18n> localizada conteúdo </ i18n>. </ help> <Tipo de valor = "default" > Autor, John </ value> </ Field></ P> |
xref
Container Texto
Elemento estrutural
O xref elemento é uma referência a um documento externo. Pode ser misturada livremente com o texto e todo o texto no interior da própria etiqueta irá ser usado como parte de corpo visual do elo.
Parente
- célula
- p
- item
- oi
Crianças
- nenhum
Atributos
- alvo : (obrigatório) Um alvo para a referência, utilizando uma URL ou um ID de um elemento existente como um destino para a referência externa .
<p> <Alvo xref = "/ url / link / target" > Este texto é mostrado como um link. </ xref></ P> |
